
26. 实现 GPT 层归一化#
26.1. 介绍#
上一节我们已成实现数据进入模型之前的数据处理流水线,本小节将开始深入GPT 模型的内部,实现其核心组件。
26.2. 环境配置#
26.2.1. 安装依赖#
!pip install --upgrade dsxllm
26.2.2. 环境版本#
from dsxllm.util import show_version
show_version()
本书愿景:
+------+--------------------------------------------------------+
| Info | 《动手学大语言模型》 |
+------+--------------------------------------------------------+
| 作者 | 吾辈亦有感 |
| 哔站 | https://space.bilibili.com/3546632320715420 |
| 定位 | 基于'从零构建'的理念,用实战帮助程序员快速入门大模型。 |
| 愿景 | 若让你的AI学习之路走的更容易一点,我将倍感荣幸!祝好😄 |
+------+--------------------------------------------------------+
环境信息:
+-------------+--------------+------------------------+
| Python 版本 | PyTorch 版本 | PyTorch Lightning 版本 |
+-------------+--------------+------------------------+
| 3.12.12 | 2.10.0 | 2.6.1 |
+-------------+--------------+------------------------+
26.3. GPT 模型架构概览#
GPT 模型预测下一个词元的过程如下:
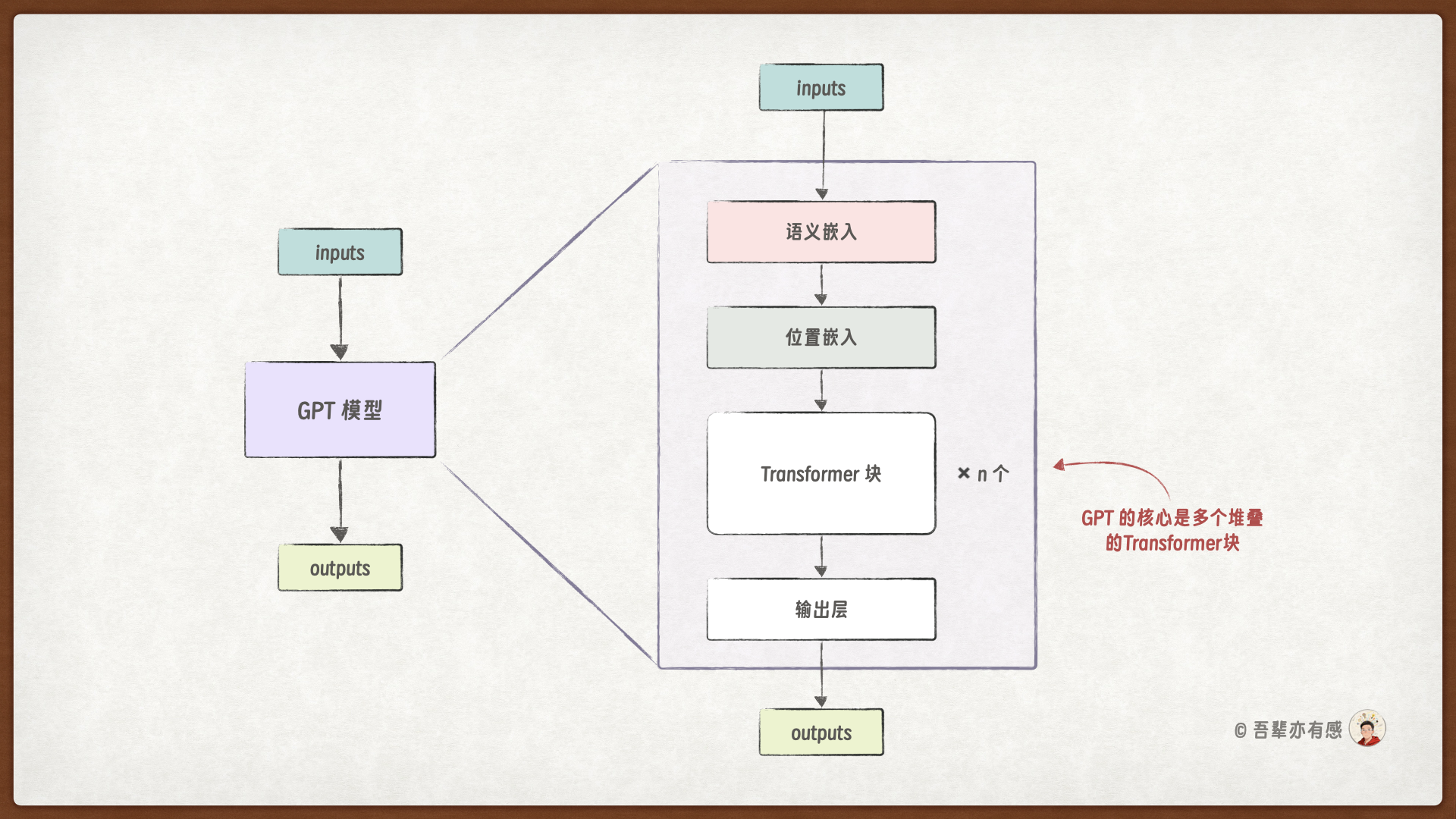
当 GPT 模型接收到输入文本后,首先对文本进行分词,得到对应的词元 ID。接着,通过词元嵌入将词元 ID 映射为向量表示,并加入位置嵌入信息以保留序列顺序。组合后的信息形成一个张量,随后经过多个堆叠的 Transformer 块进行特征提取。最后,通过一个全连接输出层将特征映射到词汇表大小的向量空间,得到每个位置上所有可能词元的预测得分。
每个 Transformer 块的架构如下:
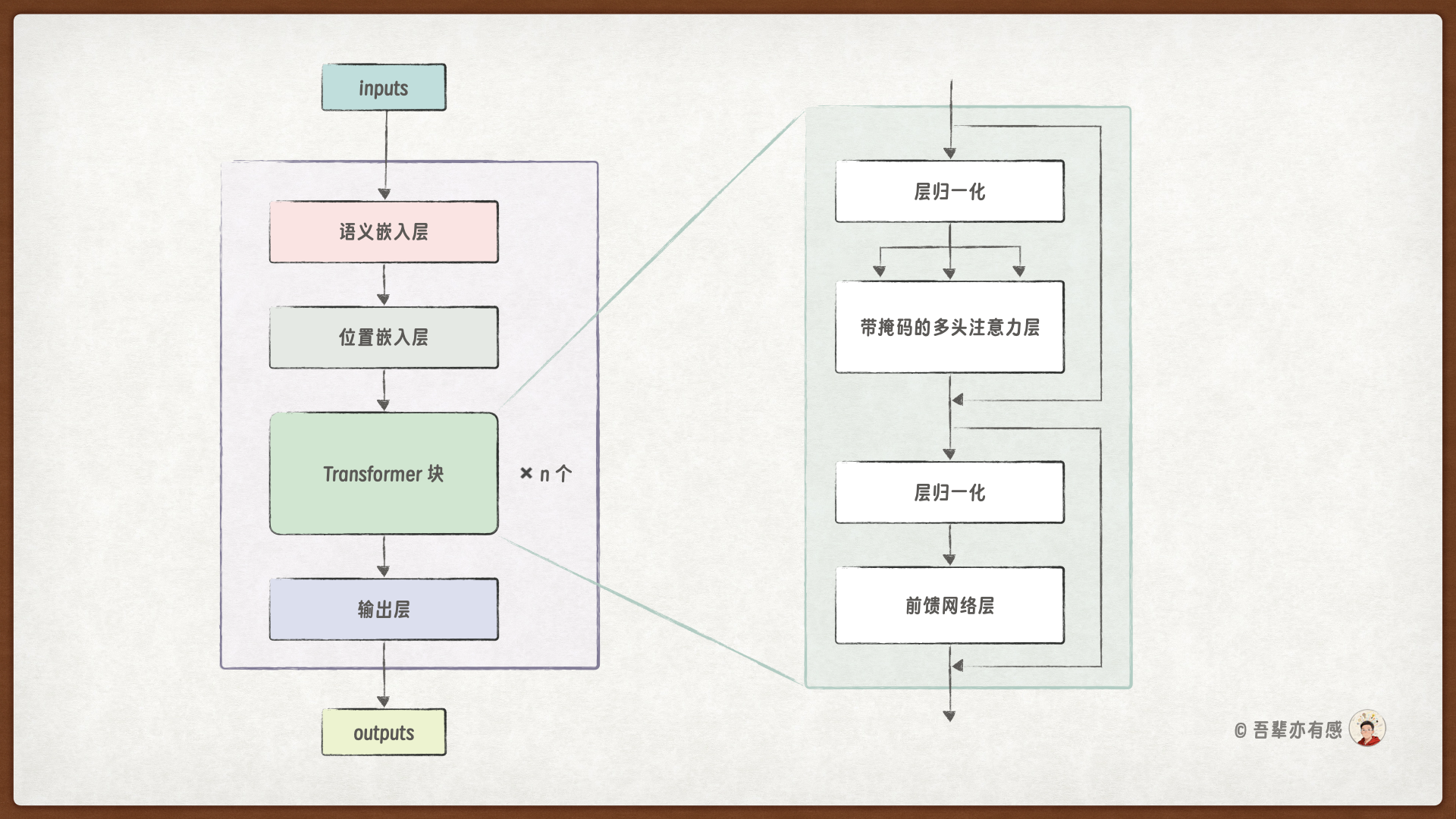
在 Transformer 块中,首先对输入进行层归一化,然后通过多头自注意力机制提取上下文特征。接着再次进行层归一化,并通过前馈神经网络进一步融合特征。整个过程均使用残差连接,以缓解梯度消失问题,稳定模型的训练过程。在上一节中,我们已经实现了 GPT 模型的词元嵌入与位置嵌入,这一小节我们将从层归一化开始逐步实现 Transformer 块。
26.4. 层归一化#
由于梯度消失或梯度爆炸等问题,训练深层神经网络有时会导致训练过程不稳定,通过层归一化调整参数的分布和大小,可以提高神经网络训练的稳定性和效率。层归一化的主要思想是调整神经网络层的激活(输出),使其均值为 0 且方差(单位方差)为 1。这种调整有助于加速权重的有效收敛。
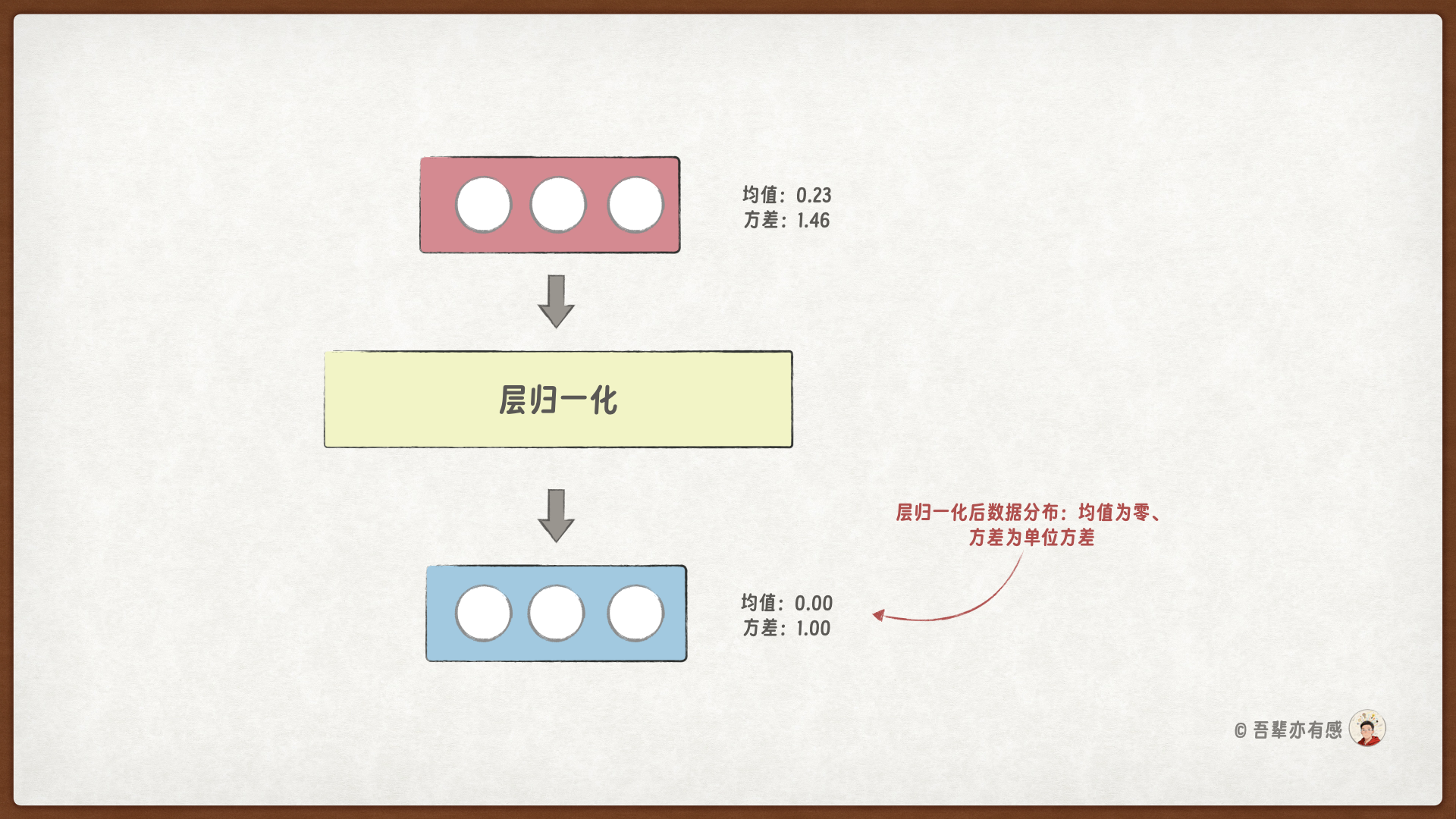
26.4.1. 层归一化的计算公式#
26.4.2. 层归一化的计算步骤#
假设我们有一个输入向量 \(x\),它代表了神经网络中某一层(例如Transformer中的前馈神经网络层或多头注意力层)的输出,这个向量有 \(H\) 个特征维度(可以理解为神经元的个数)。层归一化的计算过程可以分解为以下四个清晰的步骤,整个过程是针对单个样本,在其特征维度上进行的。具体过程如下:
步骤 1:计算均值和方差。
对于这个包含 \(H\) 个数值的输入向量,我们首先计算它的均值 \(μ\) 和方差 \(σ^2\) 。
均值计算:把向量里所有的数值加起来,然后除以特征的数量 \(H\),得到平均值 \(μ\)。
方差计算:衡量这 \(H\) 个数值偏离均值的程度。计算每个数值与均值的差的平方,把这些平方值加起来,再除以 \(H\),得到方差 \(σ^2\) 。
步骤 2:归一化。
得到均值和方差后,我们对输入向量的每一个分量 \(x_i\) 进行归一化处理。将每个数值减去均值(使其中心化为 0),再除以标准差(即方差的平方根,使其缩放到单位方差)。
为了确保计算过程防止除数为 0,会在分母上加上一个非常小的正数 \(ϵ\)。 经过这一步,原始的输入向量 \(x\) 就被转换成了一个均值为 0、方差为 1 的全新向量 \(\hat{x}\) 。此时,所有特征的数值尺度都统一了。
步骤 3:进行缩放平移,恢复与增强模型的表示能力。
数据全部变成标准的正态分布虽然稳定,但可能会破坏原始数据本身的分布特性,从而降低模型的表达能力。例如,原始数据中某些特征本身就具有较大的方差(即比较重要),这一步可能会抹掉这种差异。
为了解决这个问题,层归一化引入了两个可学习的参数:缩放参数 \(γ\) 和平移参数 \(β\)。
缩放:将归一化后的向量 \(\hat{x}\) 与 \(γ\) 逐元素相乘。\(γ\) 的作用是调整每个特征的方差(可以放大或缩小特征的重要性)。
平移:再在乘积结果上加上 \(β\)。\(β\) 的作用是调整每个特征的均值(可以决定激活函数的饱和区)。
26.5. 层归一化的代码实现#
import torch
class LayerNorm(torch.nn.Module):
"""
层归一化(Layer Normalization)。
计算公式:
y = γ * (x - μ) / √(σ² + ε) + β
其中:
- x: 输入张量
- μ: 在特征维度上计算的均值
- σ²: 在特征维度上计算的方差(无偏估计)
- ε: 一个小常数(默认为 1e-5),防止除零
- γ: 可学习的缩放参数(初始化为全1)
Args:
normalized_shape (int): 特征维度。
"""
def __init__(self, normalized_shape):
super().__init__()
# 小常数 ε,防止除零
self.epsilon = 1e-5
# 可学习的缩放参数 γ
self.scale = torch.nn.Parameter(torch.ones(normalized_shape))
# 可学习的平移参数 β
self.shift = torch.nn.Parameter(torch.zeros(normalized_shape))
def forward(self, x):
"""
对最后一维进行归一化。
Args:
x (torch.Tensor): 输入张量,形状为 (..., normalized_shape)。
Returns:
torch.Tensor: 归一化后的张量,形状相同。
"""
# 1️⃣ 计算特征维度上的均值,用于归一化
mean = x.mean(dim=-1, keepdim=True)
# 1️⃣ 计算特征维度上的方差,用于归一化(无偏=False表示使用有偏估计,样本方差直接除以样本数 n)
var = x.var(dim=-1, keepdim=True, unbiased=False)
# 2️⃣ 归一化输入 x,将其转换为零均值、单位方差的分布
norm_x = (x - mean) / torch.sqrt(var + self.epsilon)
# 3️⃣ 缩放和平移标准化后的输出
return self.scale * norm_x + self.shift
26.6. 层归一化的应用实例#
from dsxllm.util import print_table
# 创建 LayerNorm 层
emb_dim = 100
layer_norm = LayerNorm(emb_dim)
# 创建虚拟输入数据,形状为 [batch_size, seq_len, emb_dim]
batch_size = 2
seq_len = 5
dummy_input = torch.randn(batch_size, seq_len, emb_dim)
# 应用 LayerNorm 层
normalized_output = layer_norm(dummy_input)
# 在样本维度上计算输出的均值和方差
dummy_input_mean = dummy_input.mean(dim=-1)
dummy_input_variance = dummy_input.var(dim=-1, unbiased=False)
# 重新在样本维度计算输出的均值和方差,用于验证层归一化的效果
normalized_output_mean = normalized_output.mean(dim=-1)
normalized_output_variance = normalized_output.var(dim=-1, unbiased=False)
# 打印层归一化前后的数据均值和方差
print_table(
"层归一化示例",
field_names=["Information", "Value"],
data=[
[
"归一化前的数据均值",
[[round(val, 4) for val in row] for row in dummy_input_mean.tolist()],
],
[
"归一化前的数据方差",
[[round(val, 4) for val in row] for row in dummy_input_variance.tolist()],
],
[
"归一化后的数据均值",
[[round(val, 4) for val in row] for row in normalized_output_mean.tolist()],
],
[
"归一化后的数据方差",
[
[round(val, 4) for val in row]
for row in normalized_output_variance.tolist()
],
],
],
)
层归一化示例:
+--------------------+------------------------------------------------------------------------------------------+
| Information | Value |
+--------------------+------------------------------------------------------------------------------------------+
| 归一化前的数据均值 | [[0.0044, 0.1302, 0.0427, 0.0343, -0.0221], [0.1461, 0.1625, -0.0247, -0.0766, -0.0011]] |
| 归一化前的数据方差 | [[0.9218, 0.7182, 1.1604, 0.9512, 1.2055], [0.8335, 1.1403, 1.117, 0.8418, 0.94]] |
| 归一化后的数据均值 | [[-0.0, 0.0, 0.0, 0.0, -0.0], [-0.0, 0.0, -0.0, -0.0, 0.0]] |
| 归一化后的数据方差 | [[1.0, 1.0, 1.0, 1.0, 1.0], [1.0, 1.0, 1.0, 1.0, 1.0]] |
+--------------------+------------------------------------------------------------------------------------------+
26.7. 答疑讨论#
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。